Large multimodal models such as Stable Diffusion can generate, detect, and classify new visual concepts after fine-tuning just a single word embedding. Do models learn similar words for the same concepts (i.e. <orange-cat> = orange + cat)? We conduct a large-scale analysis on three state-of-the-art models in text-to-image generation, open-set object detection, and zero-shot classification, and find that new word embeddings are model-specific and non-transferable. Across 4,800 new embeddings trained for 40 diverse visual concepts on four standard datasets, we find perturbations within an $\epsilon$-ball to any prior embedding that generate, detect, and classify an arbitrary concept. When these new embeddings are spliced into new models, fine-tuning that targets the original model is lost. We show popular soft prompt-tuning approaches find these perturbative solutions when applied to visual concept learning tasks, and embeddings for visual concepts are not transferable. Code for reproducing our work is available at: visual-words.github.io.
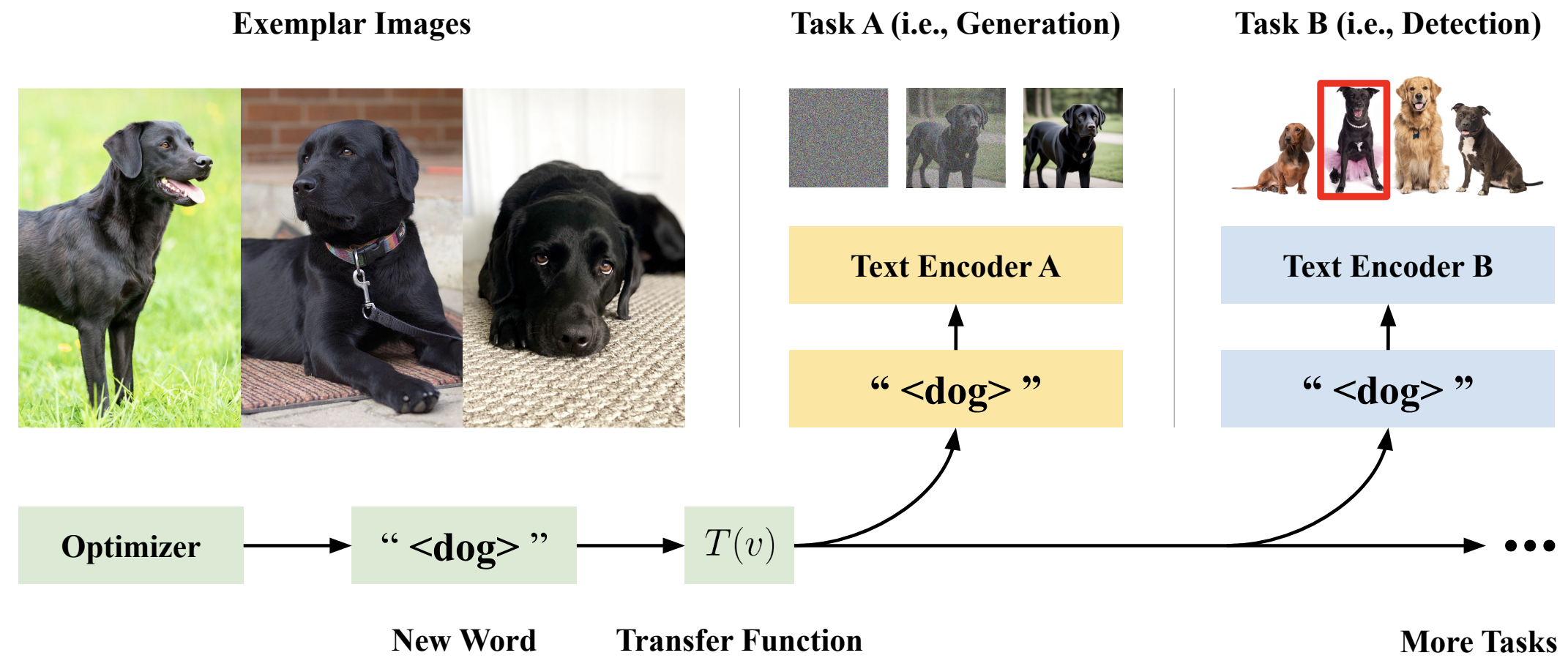
Figure 1 Large Multimodal Models, including Stable Diffusion, OWL-v2, and CLIP, can learn new words that represent specific concepts, such as <black-dog> for the black Labrador retriever on the left in the figure. Do models learn similar words for the same concept? We study the interoperability of new word embeddings that encode visual concepts across three models and tasks, and show that popular soft prompt-tuning approaches find model-specific and non-transferable solutions.
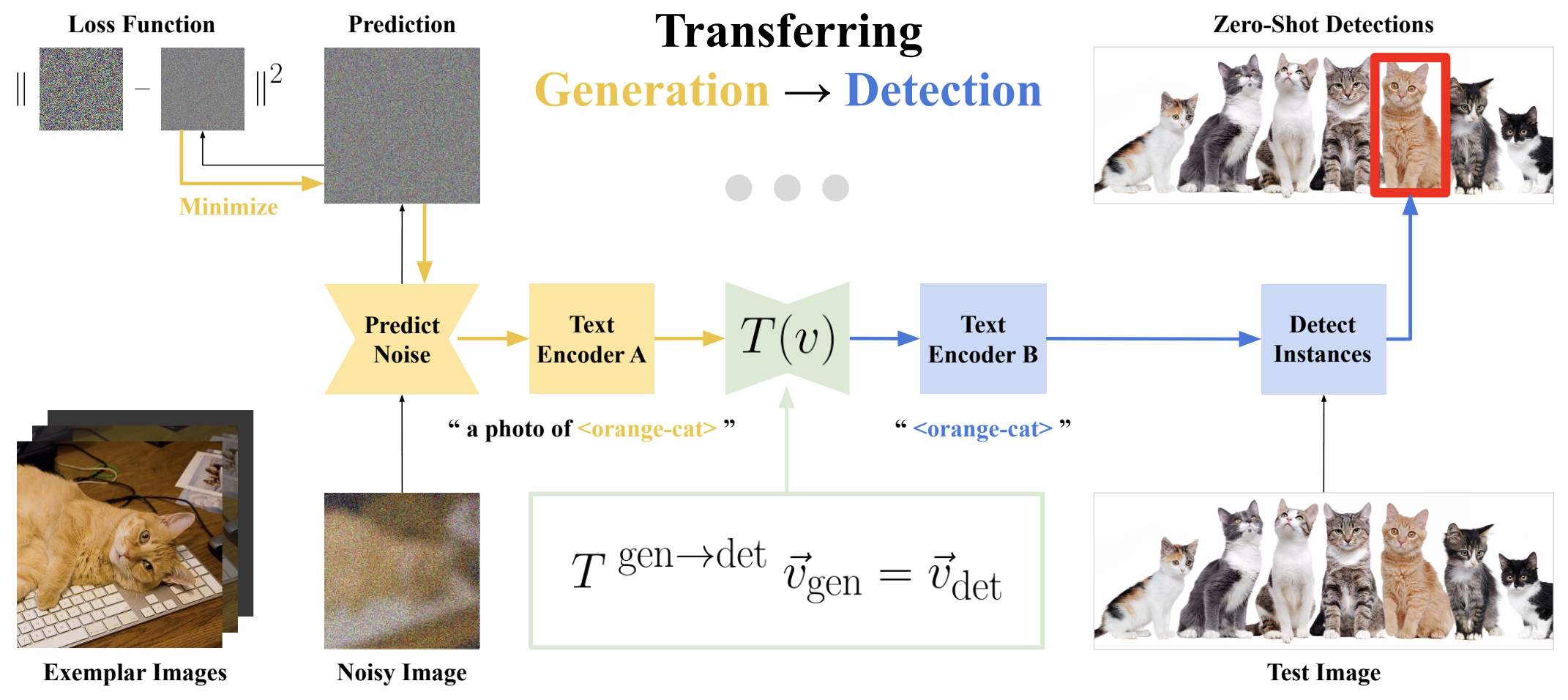
Figure 2 Transferring words optimized for generation to detection tasks. We fine-tune the vector embeddings for new words (such as <orange-cat> for the orange cat in the figure) in the Text Encoder of Stable Diffusion 2.1 to minimize a noise prediction loss for generation. Vector embeddings are transferred from generation to detection using the Transfer Function T(v⃗), and used to produce zero-shot instance detections for the target visual concept (in this case, orange cats).
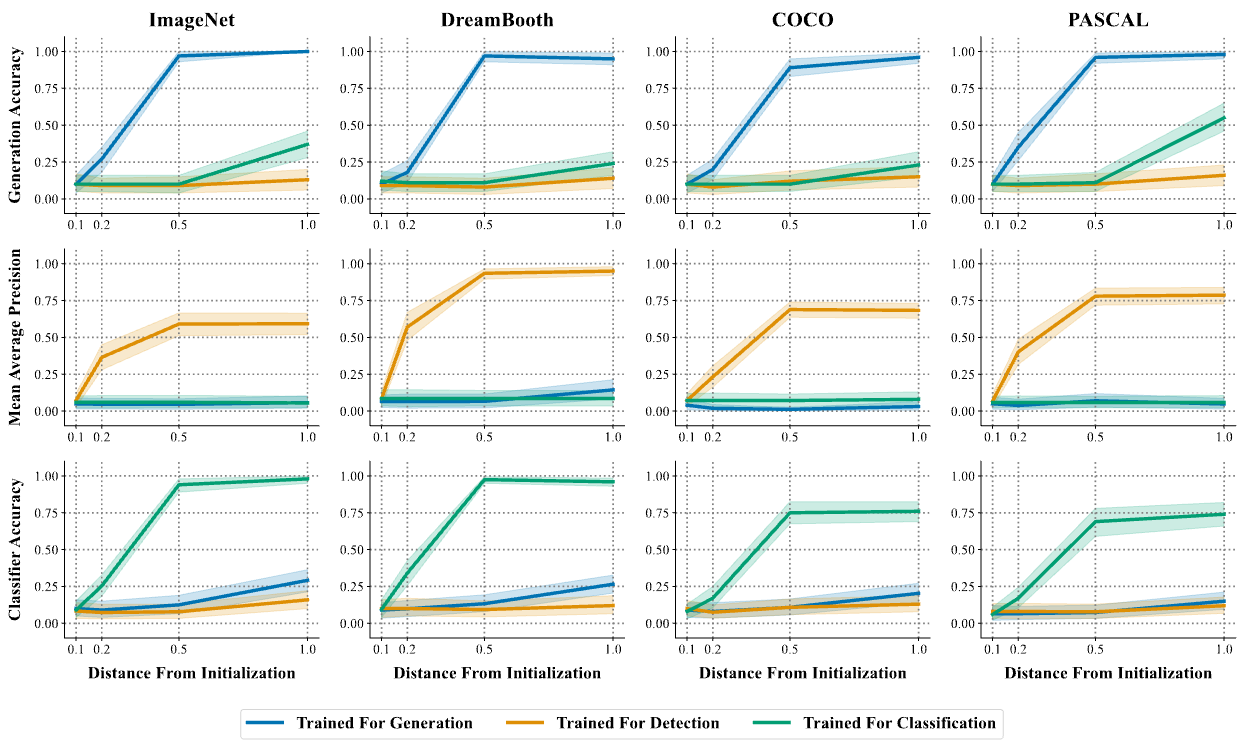
Figure 3 Performance (y-axis) of word vectors optimized for generation, detection, and classification of new visual concepts, constrained to the neighborhood of anchor words. In-domain performance saturates at a constraint level (x-axis) of δ = 0.5, where the closest word embedding is the anchor word. This type of solution performs well in-domain, but does not perform well after transfer. Each line in the figure corresponds to the 95% confidence interval of 100 randomized trials for 10 concepts, and 10 anchor words per dataset. Refer to Appendix D for the concepts and anchor words used for each dataset.

Figure 4 Performant embeddings for generation, detection, and classification are everywhere. Example generations and detections for various concepts (row labels) using solutions found in the immediate neighborhood of unrelated words (column labels). We consistently find new words for generating and detecting arbitrary concepts near unrelated anchor words across ImageNet (examples in Appendix F of the manuscript), DreamBooth (first three rows), COCO (last three rows), and PASCAL VOC (see Appendix F) datasets. The same objects are detected, and in several cases, near-identical images are generated.
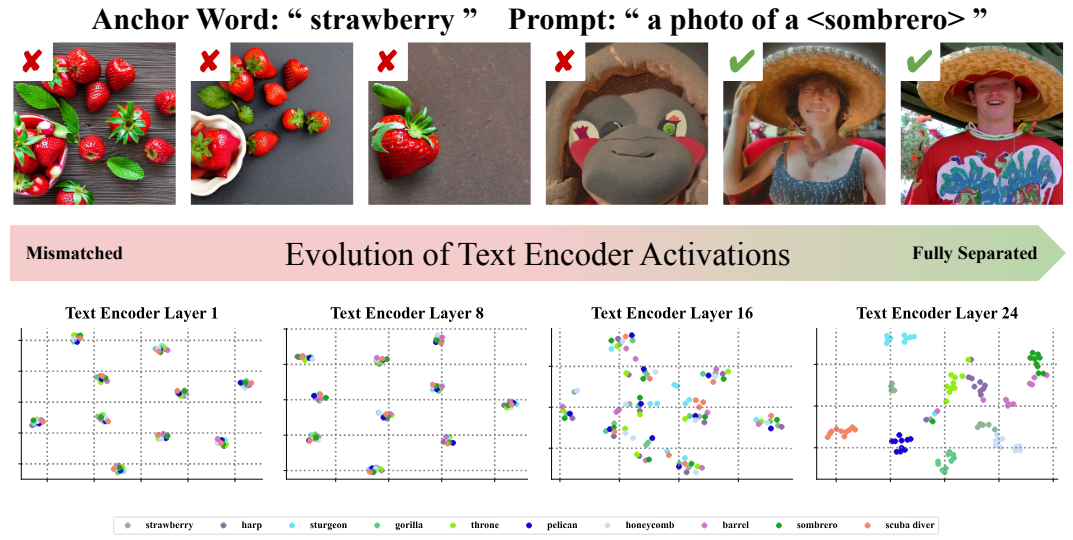
Figure 5 Prompts optimized for visual concepts target the final layers in Text Encoders. We show images generated by Stable Diffusion 2.1 when truncating the Text Encoder to the first N layers, and create TSNE visualizations of the Text Encoder activations for the pooling token at four evenly spaced layers. Each color represents a different visual concept. Activations cluster around the anchor word instead of the target concept. When truncating the text encoder to just these layers, the anchor word (i.e. strawberry) is generated instead of the target concept (sombrero). Only by the final layers are clusters and generations correct. When transferred (visualizations in Appendix G of the manuscript) no evolution happens.
@misc{trabucco2024VisualWords,
title={Understanding Visual Concepts Across Models},
author={Brandon Trabucco and Max Gurinas and Kyle Doherty and Ruslan Salakhutdinov},
year={2024},
eprint={2406.07506},
archivePrefix={arXiv},
primaryClass={cs.CV},
}